
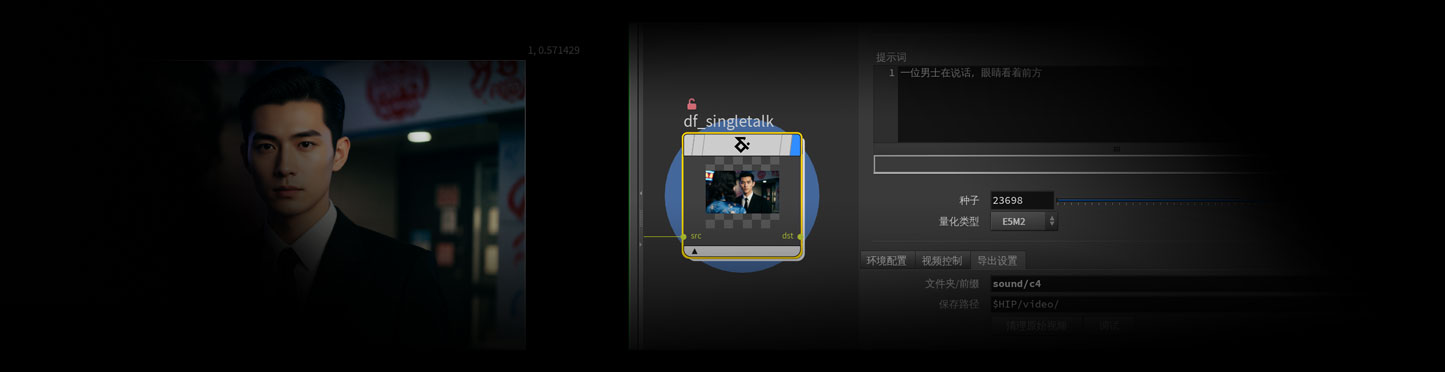

工作流介绍
DF_SingleTalk工作流基于InfineTetalk技术与Wan2.1 I2V视频模型,通过输入的角色图像与音频可以生成多时长的角色讲话视频,适合制作个人自媒体、短剧等相关视频内容。
环境配置
Comfyui插件
如果使用了整合包,则不需要单独安装插件。
- WanVideoWrapper:ComfyUI-WanVideoWrapper阿里Wan视频生成插件-数字折叠
- was-node-suite-comfyui:was-node-suite-comfyui图像数据处理插件-数字折叠
- KJNodes:ComfyUI-KJNodes 一个可以让工作流中各节点无线连接的ComfyUI节点集-数字折叠
- audio-separation-nodes:音频处理插件audio-separation-nodes-comfyui-数字折叠
- videohelpersuite:ComfyUI-VideoHelperSuite视频助手插件-数字折叠
模型下载
下载前先检查下存放路径,避免重复下载
- InfiniteTalk单人多人对话口型生成模型-数字折叠(所有模型下载)
- 阿里通义Wan视频大模型下载(kijai版)-数字折叠(图生视频模型下载480p的,其他模型全部下载)
- LightX2V视频生成加速LoRA rank128 rank64版本下载-数字折叠(建议下载rank64版本)
注意:
如果使用的是DigitFold Studio软件里的对口型工作流,text encoders 和 vae模型下载官方VAE Clip文件夹里的两个模型,再单独下载audio_encoders放到models根目录下。并且不用下载Clip_Vision模型,对口型模型下载到model_patches文件夹里。
目录结构:
? ComfyUI/
├── ? models/
│ ├── ? diffusion_models/
│ │ └─── Wan2_1-I2V-14B-480P_fp8_e4m3fn.safetensors
│ ├── ? text_encoders/
│ │ └─── umt5_xxl_fp8_e4m3fn_scaled.safetensors
│ ├── ? model_patches/
│ │ ├─── wan2.1_infiniteTalk_single_fp16.safetensors
│ │ └─── wan2.1_infiniteTalk_multi_fp16.safetensors
│ ├── ? audio_encoders/
│ │ └─── wav2vec2-chinese-base_fp16.safetensors
│ ├── ? vae/
│ │ └─── comfy-wan_2.1_vae.safetensors
│ ├── ? loras/
│ │ └─── lightx2v_I2V_14B_480p_cfg_step_distill_rank64_bf16.safetensors
参数说明
- 生成视频:点击将会执行控制图像生成讲话的视频功能。
- 启动AI:点击即可启动ComfyUI(需要 提前设置好Comfyui的路径)。
- 查看结果:执行完毕之后可以点击该按钮将生成的视频复制到你设置的保存路径里面,并且自动打开该文件夹。
- 提示词:视频生成的提示词,支持中文,根据角色性别去写,可以简单描述,例如:一位男士在说话,眼睛看着前方
- 种子:控制视频生时的随机种子
- 量化类型:选择视频模型的量化格式,如果是30系列显卡需要选择E5M2(兼容性好),如果是40系列或者更高需要选择E4M3FN(高精度,需要高端显卡).
环境配置
- Comfy路径:你的ComfyUI安装路径,启动脚本所在的文件夹。
- 服务器地址:默认填写127.0.0.1:8188
- Wan模型:选择Wan2_1-I2V-14B-480P_fp8_e4m3fn.safetensors
- 讲话模型:选择Wan2_1-InfiniTetalk-Single_fp16.safetensors
- 加速LoRA: 选择lightx2v_I2V_14B_480p_cfg_step_distill_rank64_bf16.safetensors
- vae模型:选择Wan2_1_VAE_bf16.safetensors
- clip视觉模型:clip_vision_h.safetensors
- text_encoders模型:选择umt5-xxl-enc-bf16.safetensors
视频控制
- 声音文件:选择要角色要说的话的音频文件,视频时长由该声音的时长决定
- 语音识别模型:选择models/TencentGameMate/chinese-wav2vec2-base/这个文件夹路径
- 宽度高度:视频生成的分辨率,默认832*480,如果是竖屏视频则翻转过来
- 采样步数:工作流使用了4步加速,默认可以给4
- 变化模块数量:如果显存不够,则控制该选项将一部分计算加载到内存中,最大为40
导出设置
- 文件夹/前缀:设置输出视频时在Comfyui中的OUT文件夹内的存储文件夹和视频名。
- 保存路径:该路径是点击查看结果时将生成的视频复制的路径。
- 清理原始视频:点击该按钮将会删除OUT文件夹内容的生成视频的文件夹内的所有内容。
- 调试:点击后会把当前的设置保存为一个json文件,方便直接拖入ComfyUI中生成,保存路径和视频保存路径一致。
使用方法
1.将hda下载下来,通过Houdini菜单上的Assets-Install Asset Library进行安装,或者直接放到C:\Users\yourname\Documents\houdini20.5\otls文件夹内Houdini会自动识别。
2.在houdini项目中新建一个copnet节点,进入该节点搜索创建df_singletalk节点就可以开启该工作流
3.需要通过file或者其他节点加载一张带有单独角色的图片,将这个图片连接给该工作流。
版权说明














暂无评论内容