



LightX2V视频生成加速LoRA rank128 rank64版本下载
模型介绍 LightX2V 是一个先进的轻量级视频生成推理框架,专为提供高效、高性能的视频合成解决方案而设计。该统一平台集成了多种前沿的视频生成技术,支持文本生成视频(T2V)和图像生成视频(I2V...

Wan2.2 Reward 奖励与Lightning 4步加速LoRA模型
LoRA介绍 本次我们提供了两种加速与优化Wan2.2视频生成的的LoRA,每种LoRA分别包含高噪声采样和低噪声采样的模型。 alibaba-pai/Wan2.2-Fun-Reward-LoRAs Wan2.2-Fun-Reward-LoRAs 是轻量化的奖...

视频生成运镜控制工作流DF_CameraControl
工作流介绍 DF_CameraControl工作流基于Wan2.1 I2v模型与Wan2.1 Uni3C相机控制模型,可以通过输入的三维运镜视频序列控制生成的AI视频得到相同的运镜效果。 环境配置 Comfyui插件 如果使用了整...
 会员专属
会员专属
LTX-2图像反推提示词工作流
工作流介绍 该工作流可以通过输入的图像和指令,基于Qwen3 大模型,反推出来适配LTX-2模型的图生视频提示词。 环境配置 ComfyUI工作流辅助模型-数字折叠下载里面的Qwen3-VL-4B-Instruct压缩文件...
 会员专属
会员专属
科幻建筑生成工具
工具说明 这是一个可以直接生成科幻庞大建筑的houdini工具,最终输出的是fbx模型,由于里面有大量的布尔操作,在生成的时候会有一些慢。 下面视频中的建筑就是使用该工具生成的。 工具截图 使用...

Houdini外部vex编辑器插件Houdini Expression Editor
插件作用 可以让Houdini的Wrangle节点输入框自动打开vscode编辑器,让VEX创作更舒适。 安装方法 大家可以根据自己的安装目录修改下面代码 EDITOR =D:/Program Files (x86)/vsCode/Code.exe HOUD...
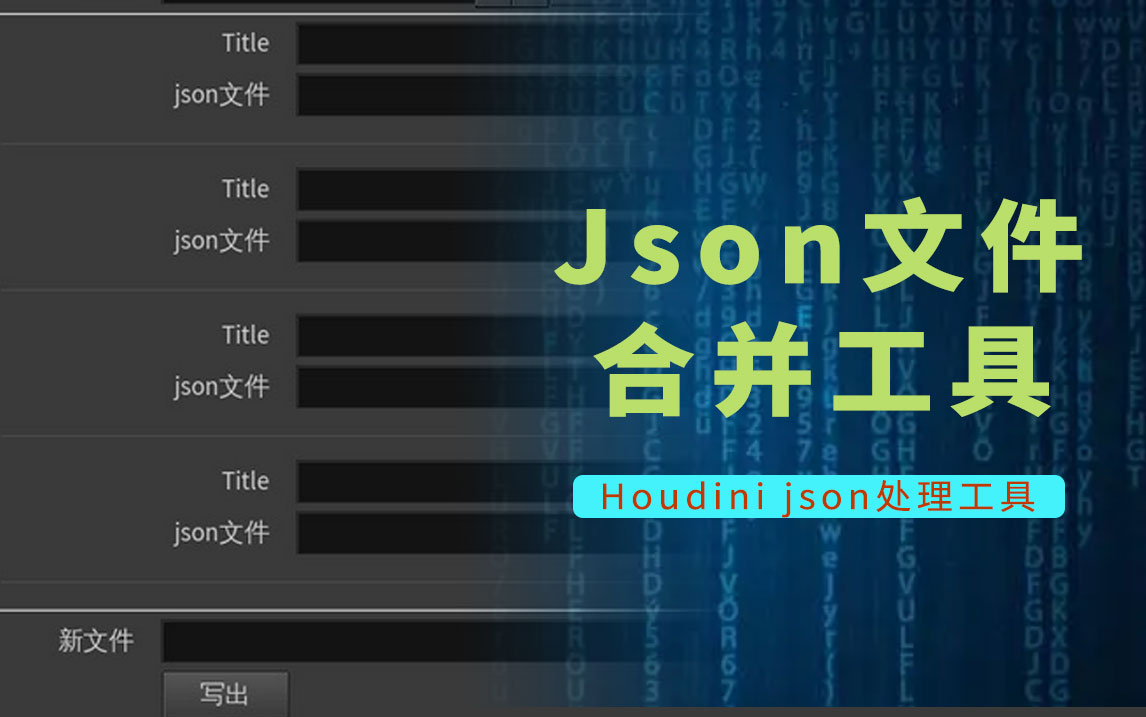
Houdini json文件合并工具
工具介绍 该工具可以将在houdini中使用json导出的多个json文件合并成为一个json文件。 请先查看如何使用json导出工具 参数说明 文件:点击加号可以参数导入的文件设置,有多少个文件要合并就创...

程序化广告牌生成工具 DF_Billboard
工具介绍 该工具可以在Houdini根据输入的文字自动生成横向或者竖向广告牌,能够自由的替换文字和字体类型。拥有不同的背板支架发光模式。可以在UE中应用。 参数说明 文字:输入广告牌上的文字,...

在Houdini中创建一个python函数并使用它
在houdini vex中有很多函数,非常的方便。但是如果想在python中使用一些个人喜好的功能就需要我们先来定义这个函数了,这篇文章主要讲的就是如何在houdini中使用python功能自定义一个小函数的方...

分辨率放大模型4x-UltraMix_Balanced
模型介绍 4x-UltraMix_Balanced 是一个用于图像超分辨率(Image Super-Resolution)的深度学习模型。它的主要功能是提升图像的分辨率,通常通过对低分辨率图像进行“放大”和细节恢复来生成更高...

ComfyUI_UltimateSDUpscale高清放大插件
插件介绍 该插件可以将图片进行高清放大,需要用到放大模型,可以到下面链接下载: 节点介绍 节点名称描述Ultimate SD Upscale这是主要的节点,拥有与原始扩展脚本大部分相同的输入。Ultimate S...

ComfyUI Segment Anything V2 (SAM2)对象分割插件
插件介绍 Segment Anything V2,又名 SAM2,是由 Meta AI 开发的突破性 AI 模型,革新了图像和视频中的对象分割。能够无缝分割图像和视频中的对象。这是第一个能够处理图像和视频分割任务的统一...

ComfyUI github版本安装包
软件介绍 该软件是Comfyui官方github上的发布版本,使用该版本可以更加深刻的理解ComfyUI的运行逻辑和环境部署。 安装方法 1.将安装包下载到本地后解压 2.解压完先运行update里面的update_comfy...
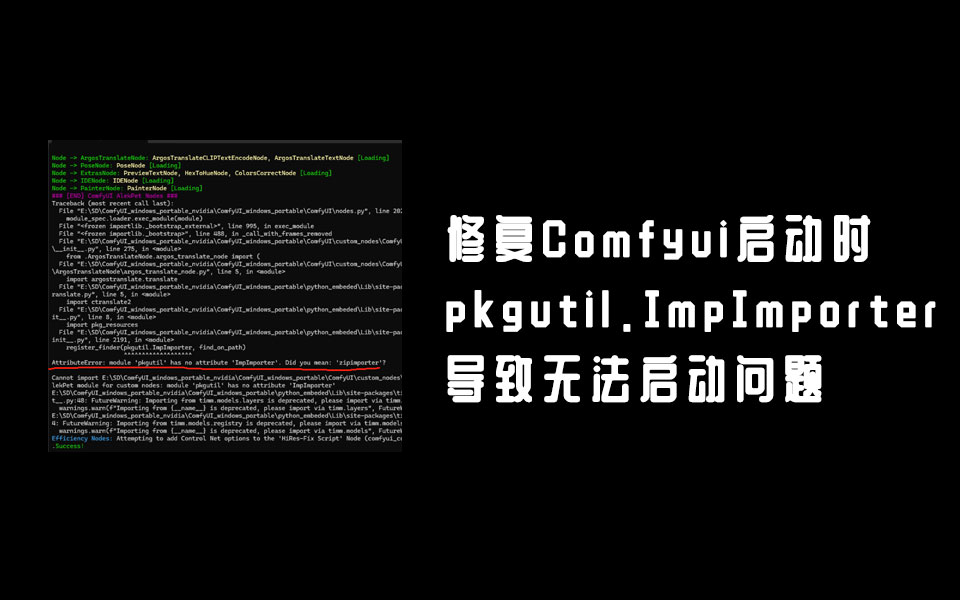
修复ComfyUI启动时报错module ‘pkgutil’ has no attribute ‘ImpImporter’问题
问题描述 我们在安装ComfyUI某些插件的时候,会使用到pkgutil.ImpImporter这个废弃的类,由于 Python 3.12 正式移除了 pkgutil.ImpImporter。所以这个时候启动软件报一下错: AttributeError: m...

Flux动漫风格LoRA softserve_anime
LoRA介绍 该LoRA可以生成二维动漫风格的图像 适配底膜 Flux dev 触发词 sftsrv style illustration 作者 alvdansenhuggingface.co/alvdansen 使用方法 将LoRA模型放到Comfyui根目录的models/lor...


