

LoRA介绍
本次我们提供了两种加速与优化Wan2.2视频生成的的LoRA,每种LoRA分别包含高噪声采样和低噪声采样的模型。
alibaba-pai/Wan2.2-Fun-Reward-LoRAs
Wan2.2-Fun-Reward-LoRAs 是轻量化的奖励调控模型(LoRA),用于在 Wan2.2-Fun 视频生成中引入人类偏好信号,提升视频与人类审美的一致性,但目前在动态一致性和避免投机取巧方面仍有限制。
Hugging Face:alibaba-pai/Wan2.2-Fun-Reward-LoRAs · Hugging Face
主要作用
- 增强视频生成效果
- 在 Wan2.2-Fun 的基础模型上加载 Reward LoRA,可以引导生成的视频更符合人类的主观偏好(比如更自然、更美观、更连贯)。
- 这些 LoRA 就像一个“插件”,不需要重新训练整个大模型,而是通过轻量化训练参数(LoRA 权重)对视频生成过程进行调节。
- 适配不同噪声阶段的模型
- 高噪声模型(High-noise model):推荐使用 HPSv2.1 Reward LoRA,收敛快,效果较稳定。
- 低噪声模型(Low-noise model):MPS Reward LoRA 收敛慢且效果差,所以也推荐使用 HPSv2.1 Reward LoRA。
- 训练能力
- 官方提供了预训练好的 Reward LoRA,可以直接使用;
- 也可以用他们提供的训练脚本,基于你自己的偏好数据再训练出一个新的 Reward LoRA,来更好地契合你想要的视频风格。
- 作为插拔式调控
- 在
predict_t2v.py脚本里,你可以通过设置lora_path、lora_weight(低噪声)和lora_high_path、lora_high_weight(高噪声)来灵活控制 Reward LoRA 的影响力。
- 在
模型包含:
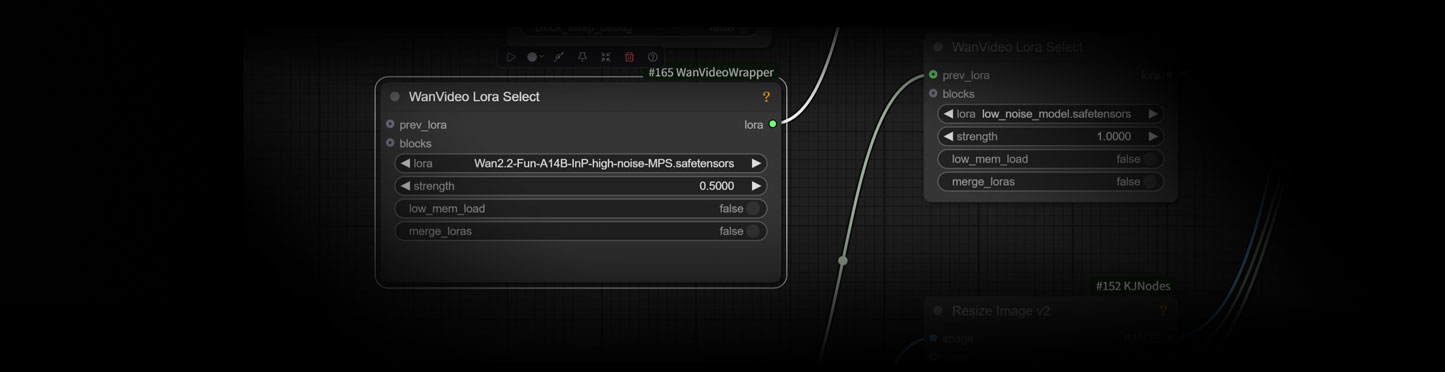
- Wan2.2-Fun-A14B-InP-high-noise-MPS.safetensors
- Wan2.2-Fun-A14B-InP-low-noise-HPS2.1.safetensors
lightx2v/Wan2.2-Lightning
它是 Wan2.2 视频生成模型的蒸馏(distilled)版本,配合 LoRA 使用,可以大幅加速视频生成过程,同时保持高质量输出。
Hugging Face:lightx2v/Wan2.2-Lightning · Hugging Face
核心作用
- 极致加速 ⚡
- 将视频生成过程压缩为 仅需 4 步(相比原本几十步甚至上百步的推理)。
- 不再依赖 CFG(Classifier-Free Guidance)技巧,直接生成结果。
- 实测 速度提升约 20 倍。
- 保持高质量 ?
- 尽管大幅减少了采样步骤,生成画面质量在多数场景下依旧与基础模型相当,有时甚至更好。
- 这是通过 知识蒸馏 + LoRA 微调 实现的,模型在少步推理中学会保留关键细节。
- 复杂运动生成 ?
- 即使只用 4 步,模型依然能生成具有丰富动态的画面(例如人物动作、镜头移动、环境运动)。
- 解决了“步数少 → 动作生硬”的常见问题。
对用户的意义
- 节省时间:几秒钟就能生成一段视频,非常适合快速迭代和预览。
- 降低显存占用:更少的采样步骤意味着显存消耗更低,中低显存显卡也能跑。
- 结合 LoRA 灵活调控:可以在 Lightning 基础上再叠加风格 LoRA 或 Reward LoRA,兼顾速度与个性化。
模型包含:
- high_noise_model.safetensors
- low_noise_model.safetensors
使用方法
将所有的LoRA都下载到Comfyui根目录的models\loras文件夹内

支持远程部署
支持需求定制
适用软件ComfyUI
底膜Wan2.2
大小3.5G
工具使用问题请联系微信 15915765126
免费资源
© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END











暂无评论内容