



ComfyUI工作流辅助模型
模型介绍 在ComfyUI执行任务的时候,除了基础的绘画、视频生成大模型,还会用它一些其他功能的辅助模型,比如:提示词反推、人脸识别 资源目录 vitmatte(遮罩提取) onnx(人像检测) SEEDVR2...

多合一控制模型FLUX.1-dev-ControlNet-Union-Pro-2.0
模型介绍 FLUX.1-dev-ControlNet-Union-Pro-2.0是由Shakker Labs最新发布的FLUX.1-dev文生图模型的多合一ControlNet。相比与1.0版本,做出了以下的改善 移除了模式嵌入,模型体积更小 在Canny和...

UE5动画库赋予给mixamo绑定角色
UE5为我们提供了大量的角色动作库,mixamo可以快速的将我们的模型进行绑定,本文主要讲的是如何把UE5的动作信息赋予给mixamo绑定的模型身上。操作步骤1.先把动作文件以及UE5角色模型,mixamo...

混元视频模型插件ComfyUI-HunyuanVideoWrapper
插件介绍 ComfyUI-HunyuanVideoWrapper是一个开源项目,旨在为HunyuanVideo提供ComfyUI的封装节点,方便用户进行视频生成和处理。它结合了最新的深度学习技术,允许用户以更直观的方式操作视频...

Comfyui风格迁移插件IPAdapter_plus(函模型下载)
插件介绍 IP-Adapter是腾讯AI实验室发布的一个专门为预训练的文本到图像扩散模型(如Stable Diffusion)设计的适配器。其主要功能是通过图像提示来生成图像,能够复制参考图像的风格、构图或人...

UE5混合材质球
素材说明 该材质球可以将不同类型的材质进行混合,基本材质贴图可以到Quixel上下载。同时我们还单独提供了材质直接的一些遮罩alpha贴图,具体使用方法我们会在一些案例操作中详细演示。 使用方...

Flux深度出图Nunchaku加速工作流
工作流介绍 df_fluxn_d2i Houdini HDA工作流的核心功能是将深度信息图片转化为AI图像。具体流程如下: 输入深度信息图片:用户首先输入一张包含场景深度信息的图片。这个图片通常包含场景中物体...
 会员专属
会员专属
UE5 PCG制作知识点梳理
PCG操作节点 这些节点是在PCG graph蓝图中使用的,并且需要先开启PCG插件,如果要执行节点,需要选择节点按键盘Ctrl Alt D。 surface Sampler:随机分布一些盒子 mesh Sampler:在输入的模型中...

Houdini模型批量提取工具_AutoBlast
工具说明 该工具可以在houdini中根据shop_materialpath属性对模型进行批量的blast节点添加,让每一部分都可以独立出来,方便我们的后续操作。 使用方法 根据Shop_Materialpath提取模型代码 根据...
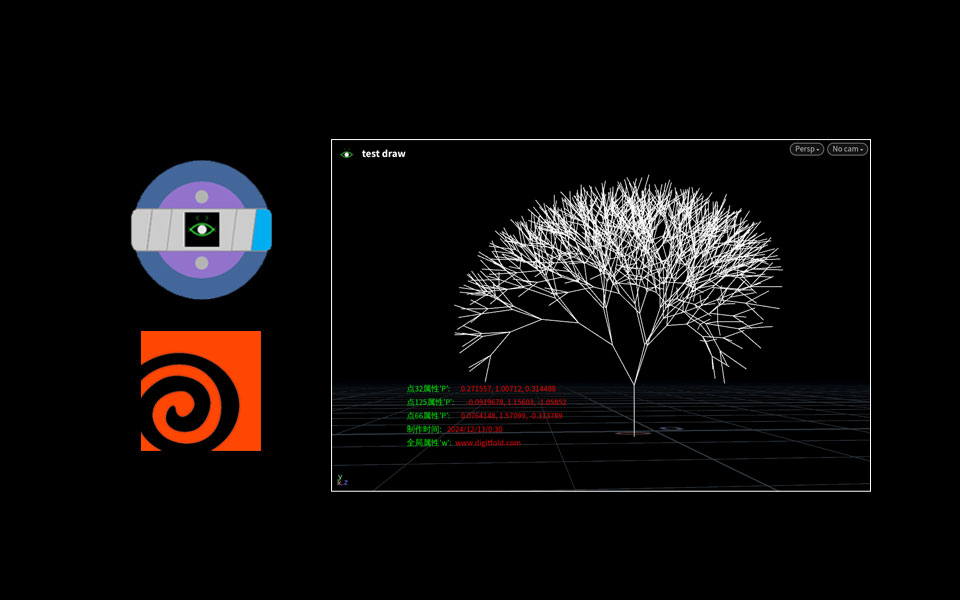
Houdini 屏幕显示属性参数工具DF_ViewAttr
工具说明 该工具主要是在houdini视窗上绘制指定的模型的某个层级的某个序号的属性值,方便独立观看属性参数,可以实时更新,并且可以指定多个属性以及控制显示的位置距离等。 视频演示 参数说明...

控制图视频转绘工作流DF_WanFun_Control
工作流介绍 DF_WanFun_Control工作流通过Wan2.1-Fun-1.3B-control视频控制模型可以将输入的控制图像(深度,骨骼)转绘为视频,并集成Florence2反推模型自动填写精确的提示词,支持自定义视频保...

UE5水材质制作技术点
创建基本材质球1.Specular给到0.35,Roughness给到0,法线贴图给到normal。2.使用Absolute World Position获取到模型世界空间位置,通过mask提取出来rg通道连给法线的uv。如果比例过于大可以在...

FLUX.1-dev-ControlNet-Union-Pro模型
模型介绍 本模型是 FLUX.1-dev-Controlnet-Union 的 Pro 版本,经过更多训练步骤和更丰富的数据集优化,具备更强的性能和更广泛的应用场景。它支持 7 种控制模式,能够灵活应对多种图像处理需求...

Houdini 实用节点总结
remove_shared_edges 基于divide节点的一个设置,可以删除面上多余的边。 remove_inline_points 基于divide节点的一个设置,可以删除线上的多余点,和face节点上的Remove Inline Points功能一样...

千问Flux提示词扩写模型Qwen2.5-7B-Instruct-Uncensored-Flux
模型介绍 qwen2.5 - 7b - instruct-uncensot-flux是一个微调模型,旨在帮助生成详细和富有想象力的提示,专门为Flux。它已经使用FluxDev ControlNet数据集(16k)和合成数据的组合进行了训练,...


