



阿里造相Z-Image系列模型
模型介绍 Z-Image 是一个强大且高效的图像生成模型,拥有 6B 参数。目前有三个变体: ? Z-Image-Turbo – Z-Image 的精简版,仅用 8 NFEs(函数评估次数)就能与领先...

Comfyui工作流自定义封装到DFStudio工具
工具介绍 该工具是comfyui工作流配置到DFStudio中的桥梁,可以让复杂的工作流进行参数提取,方便再DFStudio中使用, 使用方法 请到下面课程链接中学习 https://www.digitfold.com/mcv_course/50...
 会员专属
会员专属
动画模型AnimateDiff-LCM Motion Model
模型介绍 这是用LCM提炼成权重的动画Diff。干净,快速渲染。在低步骤下工作得很好,集与SD1.5所提供的最真实的表现。百度网盘链接中提供的文件有: animatediffLCMMotion_v10 AnimateLCM_sd15_t...

Wan2.2图生视频14B模型量化GGUF工作流df_wan22_gguf
工作流介绍 该工作流是基于 Wan-AI/Wan2.2-I2V-A14B的量化GGUF模型以及MOE自动切换采样器,通过输入一张首帧图,控制ComfyUI生成视频,并且融入Lightx2v加速LoRA,在质量和速度上相对平衡。 环...
 会员专属
会员专属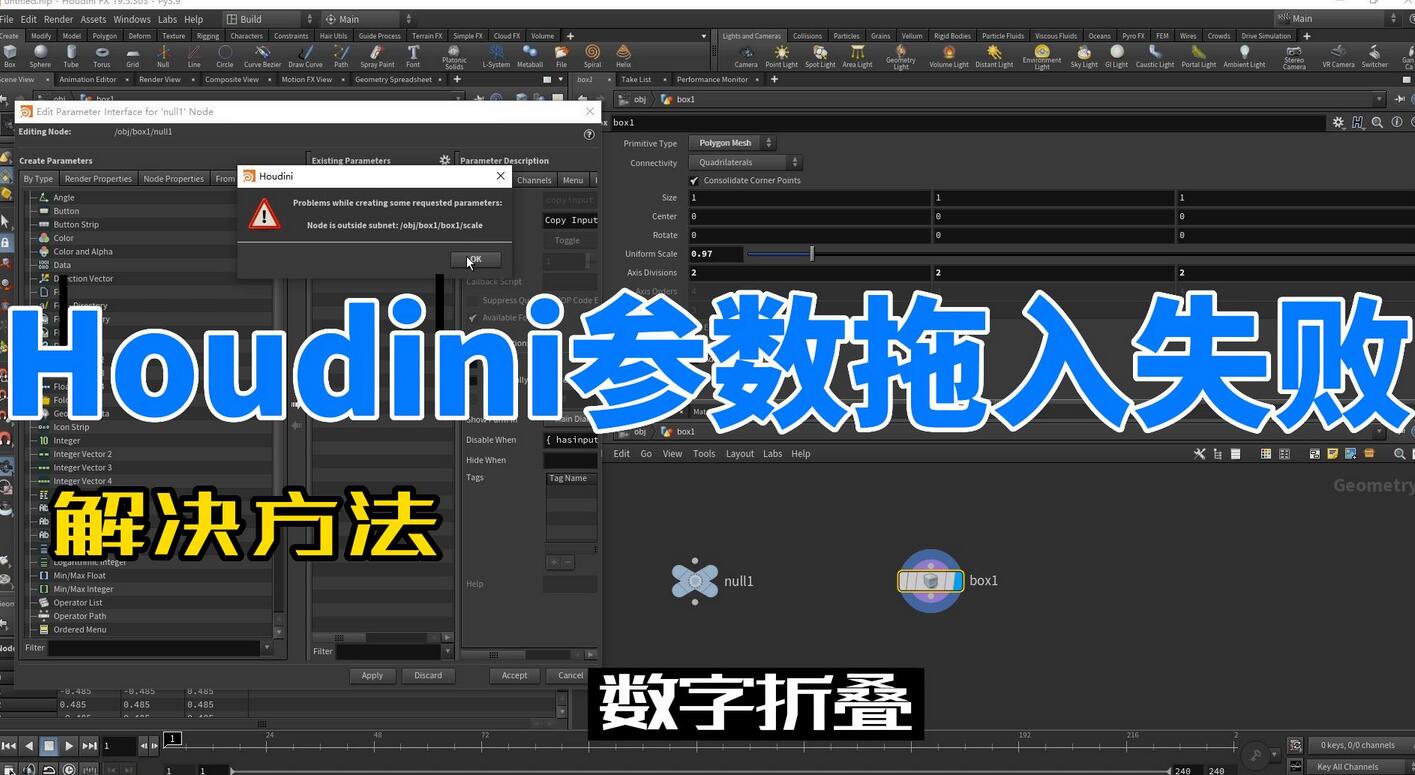


Houdini 屏幕显示属性参数工具DF_ViewAttr
工具说明 该工具主要是在houdini视窗上绘制指定的模型的某个层级的某个序号的属性值,方便独立观看属性参数,可以实时更新,并且可以指定多个属性以及控制显示的位置距离等。 视频演示 参数说明...

Comfyui_TTP_Toolset高清放大插件
插件介绍 这是基于Tile的高清放大技术,简单的说就是该插件利用了Tile技术,根据需求把图片先切割成小块,然后每一个重新采样,最后再合并,大家知道Tile是可以很大程度上保持原图构图的,只是...

分辨率放大模型4x-UltraMix_Balanced
模型介绍 4x-UltraMix_Balanced 是一个用于图像超分辨率(Image Super-Resolution)的深度学习模型。它的主要功能是提升图像的分辨率,通常通过对低分辨率图像进行“放大”和细节恢复来生成更高...



Wan-Animate(v2)14B KJ版模型
模型介绍 Wan-Animate 是一个用于角色动画和角色替换的统一模型框架。它的主要功能有两个: 角色动画生成:给定一张角色图片和一个参考视频,Wan-Animate 可以让角色“动起来”——精准复现视频...
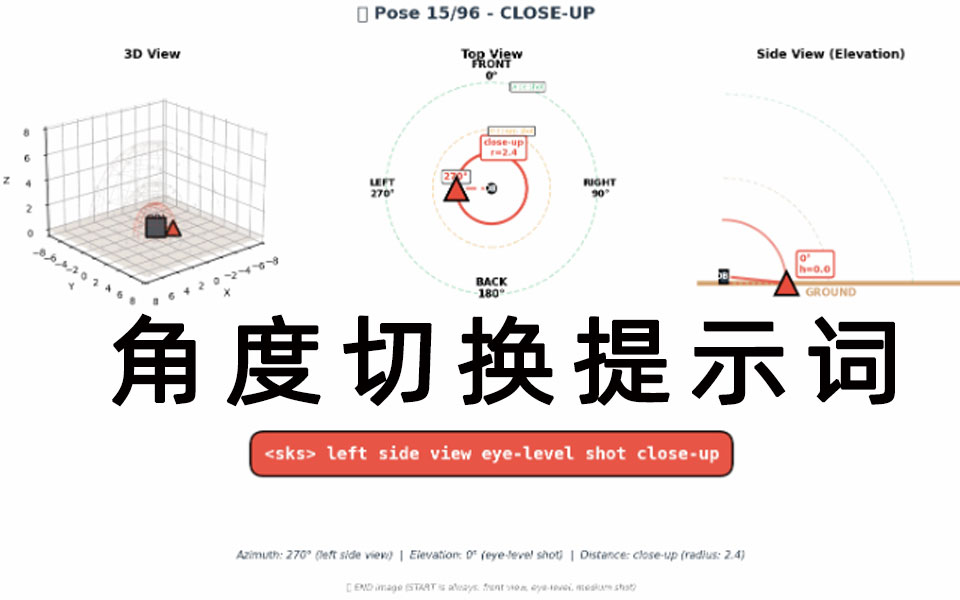
Qwen Edit 多角度编辑LoRA提示词
在线操作链接:Qwen Image Multiple Angles 3D Camera - a Hugging Face Space by multimodalart LoRA主页:fal/Qwen-Image-Edit-2511-Multiple-Angles-LoRA · Hugging Face Multi-angle LoRA ...

cg-use-everywhere ComfyUI 工作流简化插件
插件介绍 cg-use-everywhere 是由 GitHub 用户 chrisgoringe 开发的一款强大的 ComfyUI 插件。它旨在简化复杂的 ComfyUI 工作流,通过创建虚拟连接来减少节点之间的混乱连线。这个插件大大提高了...


