
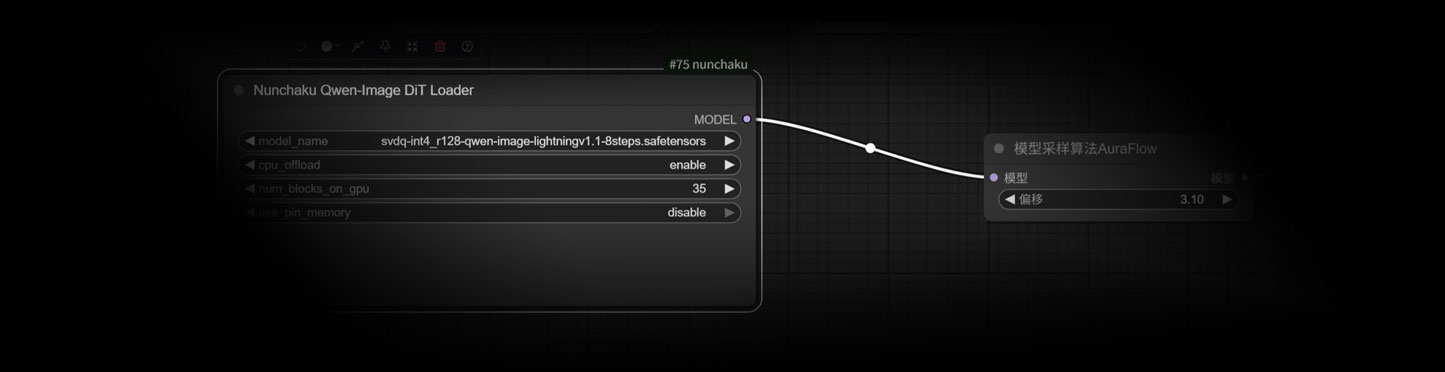

模型介绍
该模型是 Nunchaku 量化的 Qwen-Image 版本,旨在从文本提示生成高质量图像,并在复杂文本渲染方面取得进展。它针对高效的推理进行了优化,同时保持了最小的性能损失。
我们在百度网盘提供了svdq-int4_r128-qwen-image-lightningv1.1-8steps.safetensors 8步加速版本,适用于30 40 系列显卡,如果是50系列显卡请到下面链接下载fp4格式,vae和clip通用。
使用方法
- 模型:放到models\diffusion_models文件夹(svdq-int4_r128-qwen-image-lightningv1.1-8steps.safetensors)
- clip:放到\models\text_encoders文件夹(qwen_2.5_vl_7b_fp8_scaled.safetensors)
- vae:放到\models\vae文件夹(qwen_image_vae.safetensors)

支持远程部署
支持需求定制
适用软件ComfyUI
模型类型图像生成
大小11GB
工具使用问题请联系微信 15915765126
免费资源
© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END











暂无评论内容