
插件介绍
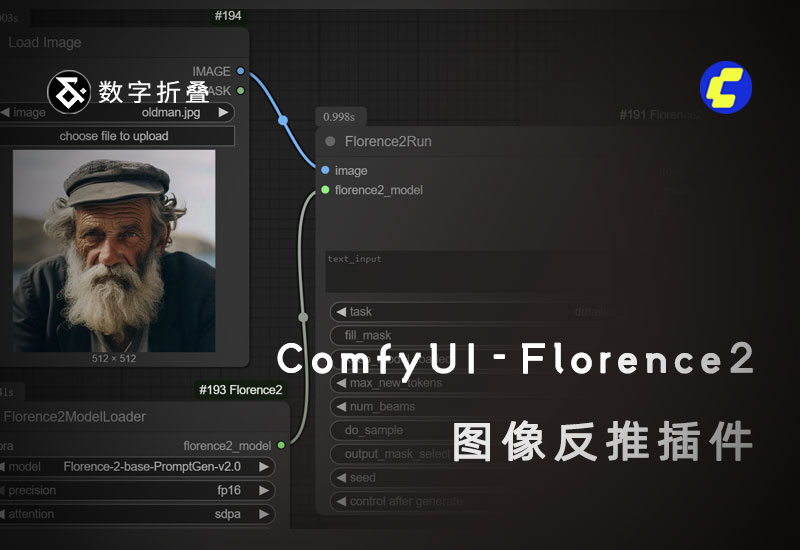
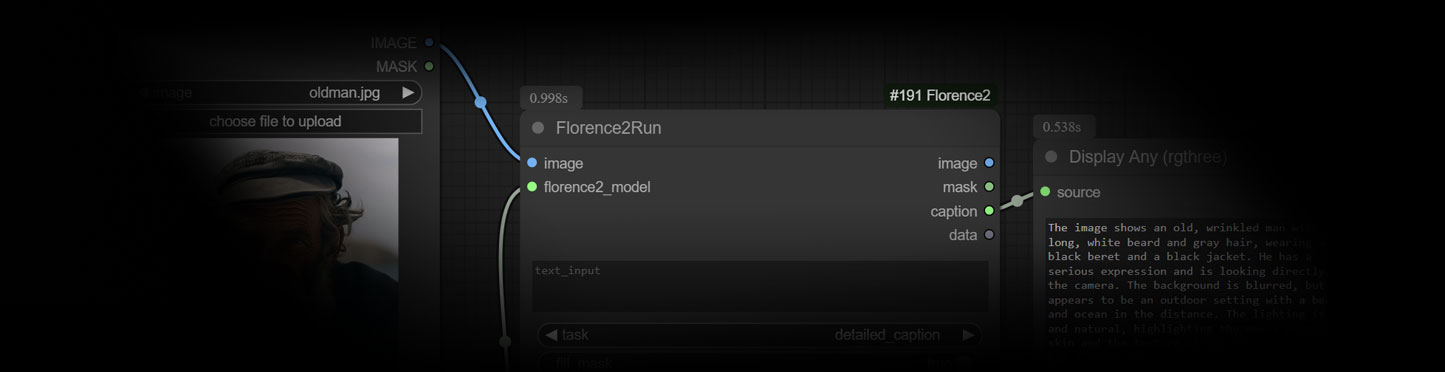
Florence-2 是一款先进的视觉基础模型,支持多种视觉和视觉-语言任务。通过简单的文本提示,它可以轻松完成图像描述、目标检测、图像分割等操作。
核心亮点:
- 图像提示词反推:直接从图像内容生成可用的文本提示词,轻松实现图像到文本的智能转换,适合提示词优化、创意生成等场景。
- 文档视觉问答(DocVQA):可对扫描文档、表格、收据等文本密集型图像提出问题,自动提取视觉和文字信息给出答案。
- 多任务学习:基于 FLD-5B 数据集(54 亿标注,1.26 亿图像),支持零样本和微调场景,性能卓越。
Florence-2 插件让 ComfyUI 用户不仅能“看懂图像”,还能“从图像生成提示词”,极大提升创作效率与智能化水平。
使用方法
插件
插件解压后(去掉-main)放到comfyui安装目录的custom_nodes目录内
模型
模型解压后将整个文件夹放到Comfyui安装目录的\models\LLM(没有LLM可以新建一个)文件夹内

支持远程部署
支持需求定制
适用软件ComfyUI
插件类型反推
大小37.2kb
工具使用问题请联系微信 15915765126
免费资源
© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END











暂无评论内容