



在Houdini中用python获取非商业版节点数据并在商业版创建
需求来源 我们有时候会拿到一些houdini hiplc文件(非商业版)作为参考,如果我们想使用里面的节点,直接复制到自己工程里面的话会把商业版文件也变成非商业版。如果自己创建相同节点并且设置一...

Houdini深度图渲染输出工具DF_DepthMap
工具介绍 我们知道,ComfyUI或者其他合成软件需要获取到图像的深度图去控制新图像的构图以及前后位置关系,那么对于CG场景来说,我们需要计算模型上的点到相机的距离从而获取一个黑白渐变的数据...
 会员专属
会员专属
ComfyUI Segment Anything V2 (SAM2)对象分割插件
插件介绍 Segment Anything V2,又名 SAM2,是由 Meta AI 开发的突破性 AI 模型,革新了图像和视频中的对象分割。能够无缝分割图像和视频中的对象。这是第一个能够处理图像和视频分割任务的统一...
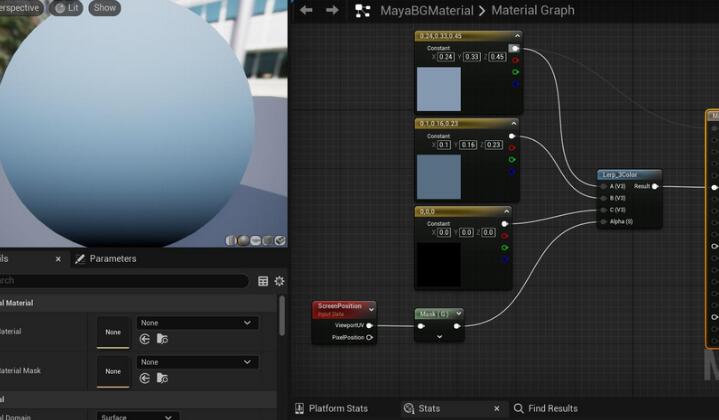
UE5基础材质
基础参数 Specular:在metalic为0,rougth不为1时,控制高光的显示,如果使用黑白贴图可以控制高光的区域。 Wold position Offset:世界位置偏移,相当于置换, 加一个三元向量,可以控制物体XY...

ComfyUI中常用节点整理
在使用ComfyUI时用到一些有意思的节点,可能过段时间就忘记了,特意整理到本文章 lmage Comparer (rgthree)可以对比两张图片的差级,连入两个输入图片之后,直接生成就可以拖动滑条查看。 Rero...

flux1-kontext-dev-fp8 图像编辑模型(非加速版本)
模型介绍 该模型是黑森林图像编辑模型Kontext的dev fp8 e4m3fn版本,可以通过提示词对模型进行更改,如果你使用的nuchaku插件的话需要下载加速版本:FLUX.1-Kontext-dev 开源模型GGUF,Nunchaku...

comfyui-ollama LLM本地模型调用插件
插件说明 该插件可以轻松地将LLM的功能集成到ComfyUI工作流中,或者只是尝试LLM推理。 要正确使用它,您需要一个正在运行的Ollama服务器,可以从运行ComfyUI的主机访问。 安装方法 插件安装 插...

混元3d插件ComfyUI-Hunyuan3DWrapper
插件介绍 ComfyUI Hunyuan3DWrapper 是一个用于集成腾讯开源的 Hunyuan3D-2 模型到 ComfyUI 的包装器。这个包装器允许用户在 ComfyUI 中使用 Hunyuan3D-2 模型进行 3D 模型生成和处理。 安装...

stable-diffusion-xl-refiner-1.0 大模型(SDXL精细化)
模型介绍 主要功能:用于对 Base 模型生成的图像进行细化,提升图像的整体质量和细节表现。 生成阶段:加载 Base 模型生成的图像后,在其基础上进行进一步的扩散步骤(通常是后期的迭代)。这个...

ComfyUI_StepAudioTTS声音克隆插件
插件介绍 基于Step-Audio-TTS的ComfyUI文本到语音节点。可以说话,说唱,唱歌,或克隆声音。 安装方法 插件安装 插件解压后(去掉-main)放到ComfyUI根目录的custom_nodes路径下。.在文件夹上面...

阿里视频控制模型Wan2.1-Fun-1.3B-Contro
模型介绍 Wan2.1-Fun-Control 是阿里团队推出的开源视频生成与控制项目,通过引入创新性的控制代码(Control Codes)机制,结合深度学习和多模态条件输入,能够生成高质量且符合预设控制条...

图像控制(深度、Pose、canny)工作流—DF_Contro
工作流介绍 该工作流基于ControlNet-Union-Pro-2.0控制模型与Nunchaku加速技术,可以快速的通过深度图、openpose以及线框图控制Flux模型生成图像,同时支持多个LoRA与高清放大。并且集成了多个...

ComfyUI-Impact-Pack图像检测增强插件(函检测模型)
插件介绍 ComfyUI-Impact-Pack 是一个为 ComfyUI 设计的自定义节点包。它的核心目标是通过一系列强大的节点,方便用户对图像进行检测(Detector)、细节增强(Detailer)、放大(Upscaler)、流...

Wan2.2VACE序列视频转绘工作流DF_SequenceRepaint
工作流介绍 该工作流基于Wan2.2 VACE与Wan2.2 T2V模型,可以根据输入的首帧色彩图像与深度(或Pose)序列图像生成最终的视频,动态完全由序列控制。 环境配置 Comfyui插件 如果使用了整合包,则...
efficiency-nodes-comfyui效率节点插件
插件介绍 efficiency-nodes-comfyui是提高工作流创造效率的工具,包含效率节点整合工作流中的基础功能,比如Efficient Loader节点相当于Load Checkpoint+Clip set layer+Load VAE等等的合集,...


