
排序

ComfyUI_UltimateSDUpscale图像放大插件
插件介绍 该插件可以对图像进行分区块放大以及细节修复,同时需要下载相应的放大模型,可在本网站搜索。 安装方法 1.将插件解压后(去掉-main)放到你ComfyUI的根目录的ComfyUI\custom_nodes文...

Comfyui ImpactPack不再提供UltralyticsDetectorProvider节点
我们在使用Comfyui进行脸部细节重绘的时候会用到一个UltralyticsDetectorProvider(检测加载器)节点,之前是安装了ImpactPack就可以找到它,但是现在没有了,查找了下这个插件的官方才知道,新...

ComfyUI_LayerStyle图像图层操作节点
节点介绍 一组为ComfyUI设计的节点,可以合成图层达到类似Photoshop的功能。这些节点将PhotoShop的一部分基本功能迁移到ComfyUI,旨在集中工作流程,减少软件切换的频率。 安装方法 插件解压后...

Flunx官方canny depth ControlNet LoRA模型
模型介绍 本次提供了两个LoRA,分别是: flux1-canny-dev-lora.safetensors flux1-depth-dev-lora.safetensors 相对于原始的Flux ControlNet模型LoRA会更小,但是出图质量差别不大 安装方式 将...

ComfyUI-VideoHelperSuite视频助手插件
插件介绍 该插件可以在ComfyUI中处理基本的视频操作,例如加载视频,合并视频等。 安装方法 插件解压后(去掉-main)放到ComfyUI根目录的custom_nodes路径下。.在文件夹上面输入cmd打开脚本编辑...

Comfyui ControlNet 预处理器节点 ComfyUI-ControlnetAux
模块介绍 ComfyUI's ControlNet Auxiliary Preprocessors 是一个用于生成 ControlNet 提示图像的 ComfyUI 节点集合。该项目的主要目的是简化 ControlNet 预处理器的使用,使其更加易于集成...

Juggernaut_X_RunDiffusion写实角色模型
模型介绍 细节表现:Juggernaut XL在人物的表现力方面非常逼真,能够绘制出细腻的肤质和光影效果,同时对手部、脚部和皮肤细节有显著提升1。 场景适应性:该模型不仅在人物描绘上表现出...

ComfyUI-Impact-Pack图像检测增强插件(函检测模型)
插件介绍 ComfyUI-Impact-Pack 是一个为 ComfyUI 设计的自定义节点包。它的核心目标是通过一系列强大的节点,方便用户对图像进行检测(Detector)、细节增强(Detailer)、放大(Upscaler)、流...

TheMistoAI/ComfyUI-Anyline线框预处理器插件
插件介绍 该插件提供了一个TheMisto.ai Anyline节点,可以将图片转换为线稿图,然后配合ControlNet的相关canny或line相关模型进行图片重绘。除了该节点,相同的功能也可以使用comfyui controlne...
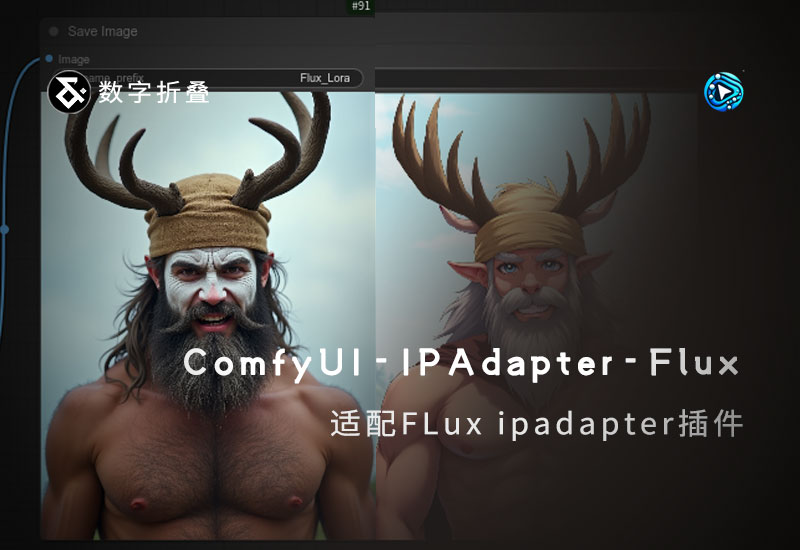
ComfyUI-IPAdapter-Flux 适配flux模型IPAdapte插件
插件介绍 Flux风格参考IPAdapter:丰富的风格选择,提升创造力 ComfyUI的Flux功能,以其丰富的风格选择而备受关注。无论你是艺术家、设计师还是摄影爱好者,Flux都能帮助你选择合适的风格,提升...

Cuda12.8环境下升级Comfyui的triton与SageAttention
问题描述 一些新的功能需要更高的cuda驱动版本,但是我们升级完cuda之后,之前的一些配套环境也需要先升级为相匹配的版本。 升级方法 PyTorch 1.安装相匹配的Pytorch轮子:download.pytorch.org...
 会员专属
会员专属
FLUX.1-Redux-dev模型
模型介绍 FLUX.1 Redux [dev] 是专为 FLUX.1 文本到图像基础模型 FLUX.1 [dev] 和 FLUX.1 [schnell] 设计的适配器。它通过提供一个简单而有效的过程,使用户能够生成迷人的图像变化。只需输入图...

ComfyUI_Comfyroll_CustomNodes自定义节点插件
插件介绍 该插件集合了一些常用的节点工具,例如放大图像,图像对比等节点。 安装方法 插件解压后(去掉-main)放到ComfyUI根目录的custom_nodes路径下。

不同大模型的后缀文件格式介绍
在大型深度学习模型的上下文中,.safetensors、.bin 和 .pth ckpt 文件的用途和区别如下: 1.safetensors 文件: 这是由 Hugging Face 推出的一种新型安全模型存储格式,特别关注模型安全性、隐...

mvadapter多角度生成模型mvadapter_i2mv_sdxl
模型介绍 本次提供固定是MV-Adapter插件的根据一张图片就可以生成多角度图像的模型mvadapter_i2mv_sdxl,为三维建模、LoRA训练等角色制作相关的流程带来便利。除此之外,我们还提供了mvadapter_t...


